Face à la multiplication des données accessibles en ligne, savoir collecter, qualifier et interpréter des informations ouvertes est devenu un enjeu stratégique majeur pour les entreprises, les institutions publiques et les organisations internationales. L’open source intelligence (OSINT) s’impose ainsi comme une compétence clé pour analyser des environnements complexes, anticiper les risques et éclairer la prise de décision.
C’est dans ce contexte que deux élèves d’Albert School, Baptiste et Alexandre, ont conçu un cas pédagogique consacré à l’OSINT appliquée à la gestion des risques et à la stratégie. Loin d’une approche uniquement théorique, ce dispositif propose aux étudiants d’entrer dans une démarche d’analyse proche de celle des praticiens : identifier des sources ouvertes pertinentes, interroger la fiabilité des informations, croiser les données et structurer un raisonnement stratégique à partir d’éléments parfois fragmentaires ou incertains.

Baptiste (à gauche) et Alexandre (à droite)
Cette initiative étudiante illustre la pédagogie portée par les formations conjointes Mines Paris – PSL x Albert School, fondée sur l’apprentissage par la pratique et la production de savoirs par les élèves eux-mêmes. En faisant de l’OSINT un objet d’étude et un outil pédagogique, ce cas permet d’aborder des enjeux contemporains essentiels — qualité de l’information, biais cognitifs, décision en environnement incertain — tout en développant des compétences hybrides, à la croisée de la data, des sciences sociales et du management.
Le cas rédigé par les étudiants est présenté ci-dessous dans son intégralité.
L’open source intelligence au service de la gestion de risque et de la stratégie.
Qu’est ce que l’open source intelligence ?
L’Open Source Intelligence (OSINT), ou collecte et analyse d’informations issues de sources dites ouvertes (réseaux sociaux, médias, registres publics, sites d’entreprises et de commerce, open data, etc.), s’impose aujourd’hui comme un levier stratégique pour les acteurs publics et privés. Son champ d’application est vaste, et peut ainsi être utilisé pour du renseignement, de la veille économique, de la prévention de risques ou encore de la planification territoriale.
L’OSINT est aujourd’hui présente à hauteur de 80 à 90 % parmi les informations exploitables dans des contextes opérationnels, et son marché est estimé à 5 milliards de dollars avec une croissance annuelle moyenne de 25 %, pouvant atteindre les 60 milliards de dollars d’ici 2033. D’autant que dans ses usages business, l’utilisation de l’OSINT permet des apports mesurables : +55 % de productivité analytique et 268 % de ROI sur 3 ans, permettant une réduction des coûts, une réduction des risques, un gain d’avantage concurrentiel et une aide stratégique de premier plan.
Cependant, l’important n’est pas seulement ce que disent les données ouvertes, mais comment elles structurent ensemble un raisonnement ou un schéma.
L’objectif est donc d’aligner ce raisonnement avec l’expérience métier et d’en faire des arbitrages techniques, pouvant répondre à la planification, à la prévention et à la décision. Nous aborderons chacune de ces questions par l’exemple de Business Deep Dive (cas pratiques), organisés par Albert School x Mines Paris et durant chacun 3 semaines.
Planifier l’action publique efficacement
Planifier l’action publique, c’est tout d’abord décider où et comment agir pour maximiser l’impact des moyens de l’État. Longtemps fondées sur l’expérience et l’intuition, ces démarches peuvent aujourd’hui s’appuyer sur l’OSINT.
Dans le cadre de ce cas, nous avons pu utiliser l’OSINT pour identifier les zones prioritaires d’implantation de structures dédiées à la jeunesse pour le MinArm, les Centres du Service National et de la Jeunesse (CSNJ), avec comme principal objectif de rendre ces dispositifs plus accessibles, mieux répartis et plus cohérents avec les besoins réels des territoires.
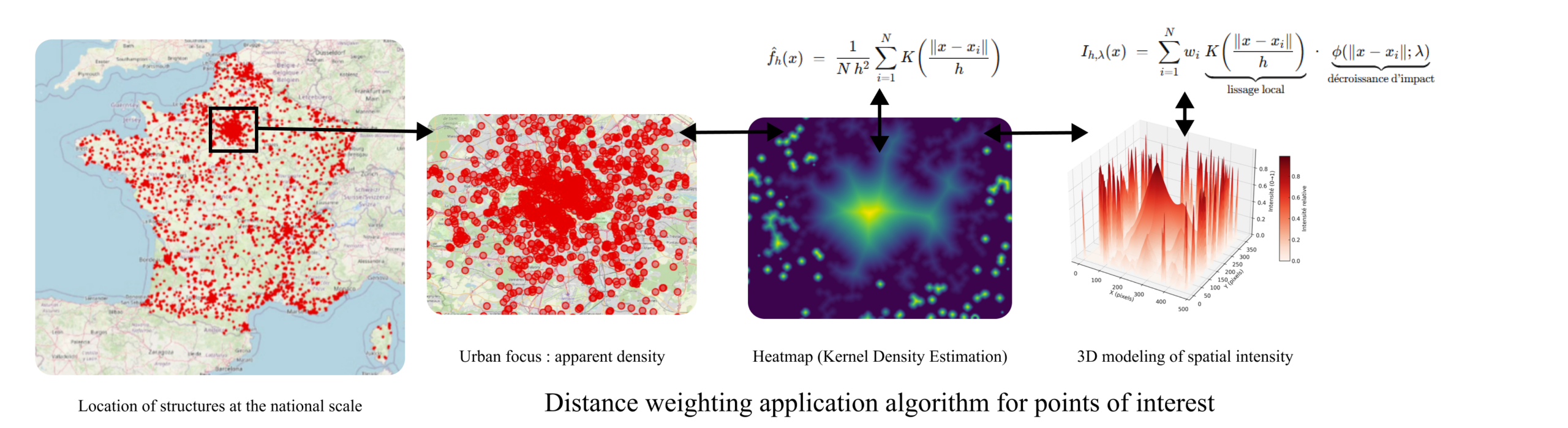
Face à cette nécessité, un modèle doit pouvoir approcher au mieux les besoins réels. De ce fait, nous devons prendre en considération des données institutionnelles, socio-économiques et spatiales, ainsi que leur portée d’intérêt. Nous devons donc croiser différentes données publiques comme celles de l’INSEE, de Data.gouv.fr, des sites de structures similaires, de Google Maps, dans le but de créer une base géospatiale commune.

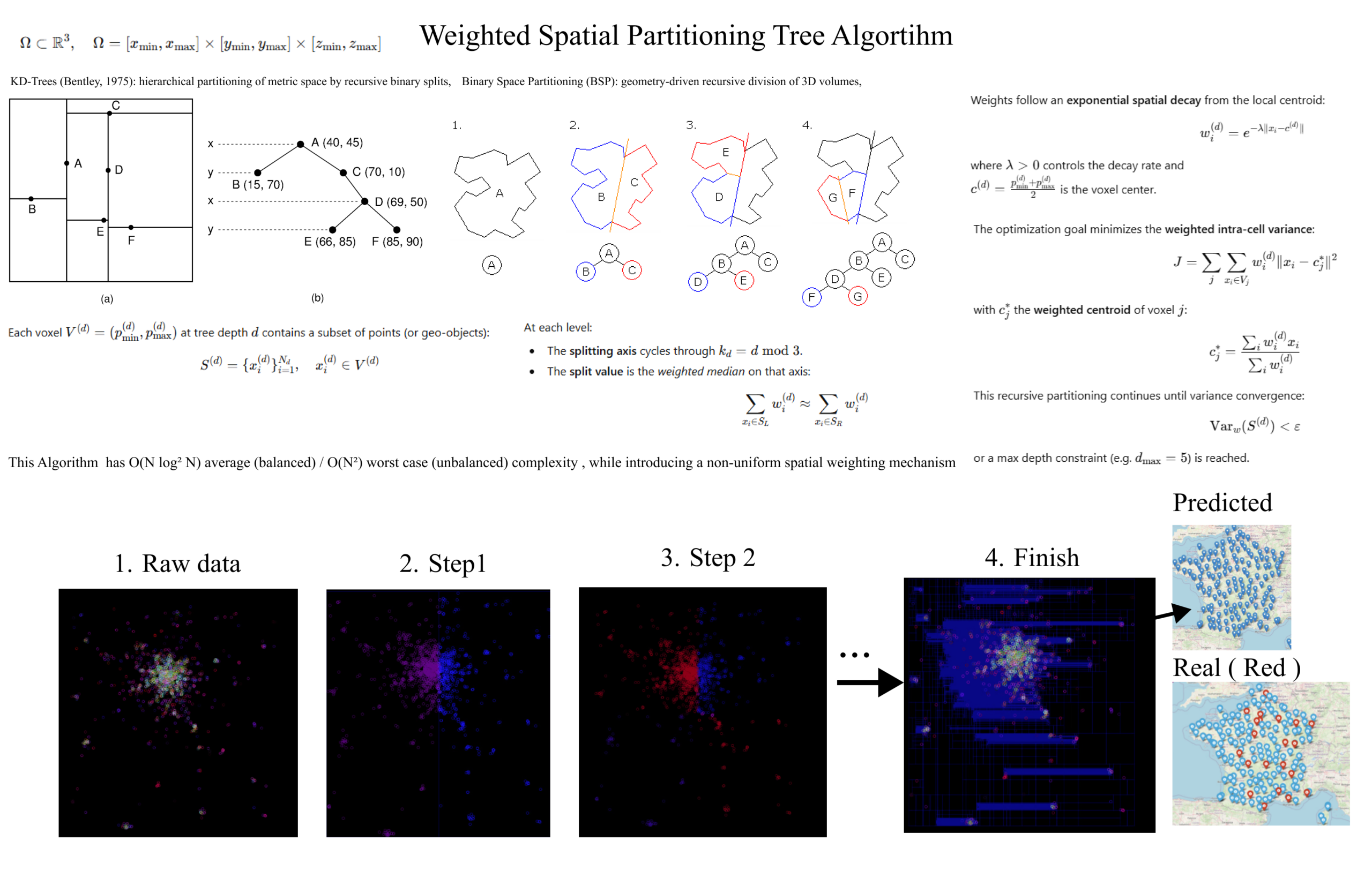
Afin de déterminer le plus exactement possible des localisations idéales pour des implémentations de CSNJ, nous devons procéder à une segmentation progressive du territoire en divisant l’espace géographique en sous-ensembles homogènes, prenant en compte la densité démographique, les indicateurs socio-économiques et la proximité avec les infrastructures existantes.
L’algorithme, écrit en C, est une adaptation avancée du KD-Tree (une structure initialement conçue pour accélérer les recherches dans un espace multidimensionnel). Ainsi, dans sa version initiale, le KD-Tree découpe l’espace en sous-zones selon un axe choisi, de manière à organiser efficacement des points dans un espace géométrique, et dans ce cas précis, l’arbre est utilisé pour comprendre la structure du territoire, pondérer les zones d’intérêt et révéler les régions où l’action publique est la plus pertinente.

Prévenir les risques grâce aux indicateurs d’actions publique
L’Open Source Intelligence (OSINT) offre aujourd’hui un potentiel considérable pour la gestion et la prévention des risques. En exploitant des sources de données publiques, librement accessibles, qu’il s’agisse d’open data gouvernementale, de bases d’accidents, d’indicateurs socio-économiques ou encore de réseaux de transport, il devient possible de construire des modèles prévisionnels afin d’appréhender le risque à un niveau de granularité jusqu’ici difficile à atteindre. Dans le domaine assurantiel, où les méthodes d’évaluation du risque restent largement agrégées à l’échelle régionale ou socio-démographique.
En particulier, le croisement entre données de terrain (issues des fichiers BAAC : Bulletins d’Analyse des Accidents Corporels sur 10 ans),et données territoriales de l’INSEE et infrastructures ouvertes (routes, transports, densité, luminosité, etc.). Cela permet d’établir un indice de risque contextuel par segment de route, exprimé sur une échelle de 0 à 100. Ce score traduit la probabilité pondérée d’accident grave ou mortel, ajustée pour chaque condition environnementale et chaque type de véhicule. Ce modèle d’OSINT permet de projeter spatialement le risque réel sur un trajet donné, une ville, voire un quartier. Il devient ainsi possible de mesurer le risque d’accident d’un conducteur, non plus à partir de son profil, mais à partir de ses itinéraires réels.
Le moteur repose sur un ensemble de traitements géospatiaux et statistiques permettant d’associer à chaque segment routier un risque calculé à partir des accidents historiques.
Chaque accident est géoréférencé, normalisé (correction des latitudes/longitudes, transformation en projection Lambert 2154) et enrichi de métadonnées : Vitesse maximale autorisée (VMA), Catégorie de route (catr) : nationale, départementale, communale, Circulation et surface (circ, surf), Catégorie du véhicule (catv), Gravité corporelle (grav) : mortel, blessé grave, léger. Ces attributs sont ensuite combinés dans deux multiplicateurs : pour les conditions de lieu et pour le type de véhicule. Chaque point d’accident reçoit ainsi une valeur pondérée de sévérité ajustée.
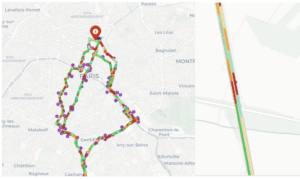
Visualisation du risque par zone
Les points d’accidents sont ensuite rattachés à des segments de route découpés tous les 100 à 250 mètres. Le code utilise pour cela un KDTree qui permet la spatialisation du risque, permettant d’assigner chaque accident au segment le plus proche dans un rayon de 22 m à 28 m. On applique alors un lissage spatial gaussien (une méthode permettant de neutraliser en partie les effets des échantillons trop faibles) où chaque segment est comparé à ses voisins dans un rayon compris entre 80 et 120 m, avec une pondération exponentielle et un facteur d’atténuation (tout ceci équivaut à une moyenne mobile géographique et rapproche la méthode du krigeage géostatistique — pour en savoir plus : Fonctionnement du Krigeage — ArcGIS Pro).
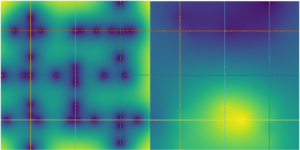
Visualisation de l’application avec un cas simple
Afin d’obtenir un algorithme exploitable et ainsi permettre une comparaison interrégionale, une échelle logarithmique normalisée est utilisée, permettant alors aux segments ou aux patterns les plus dangereux d’obtenir des scores supérieurs (grande courbure, carrefours, zones périurbaines rapides…).
Cependant, ce modèle ne serait pas proche de la réalité observable s’il ne permettait pas de simuler des itinéraires alternatifs entre deux points, et cela en reproduisant de manière proche la logique de l’algorithme A*, en y intégrant des contraintes de temps et de probabilité de trajet, où chaque itinéraire k est associé à une probabilité pondérée par la différence de distance et de temps, donnant alors une expression de l’espérance du risque global, l’arbitrage entre la durée et la distance par une simulation de Monte Carlo (MCS)
Décider sur la base d’intelligence stratégique alternative
Décider, dans un environnement saturé d’informations et soumis à des chocs systémiques permanents, exige une capacité à hiérarchiser, anticiper et rationaliser la complexité. L’intelligence stratégique alternative vise précisément à cela : comprendre avant de prévoir, prévoir avant d’agir.
Nous pouvons retrouver cette logique dans plusieurs domaines et notamment celui financier, avec par exemple la gestion d’actifs.
L’objectif pourrait être donc d’imiter le processus cognitif d’un comité d’investissement au sein d’une société de gestion, en ne s’appuyant pas seulement sur des données financières, mais également sur un ensemble de signaux faibles, comportementaux à l’aide de l’OSINT.
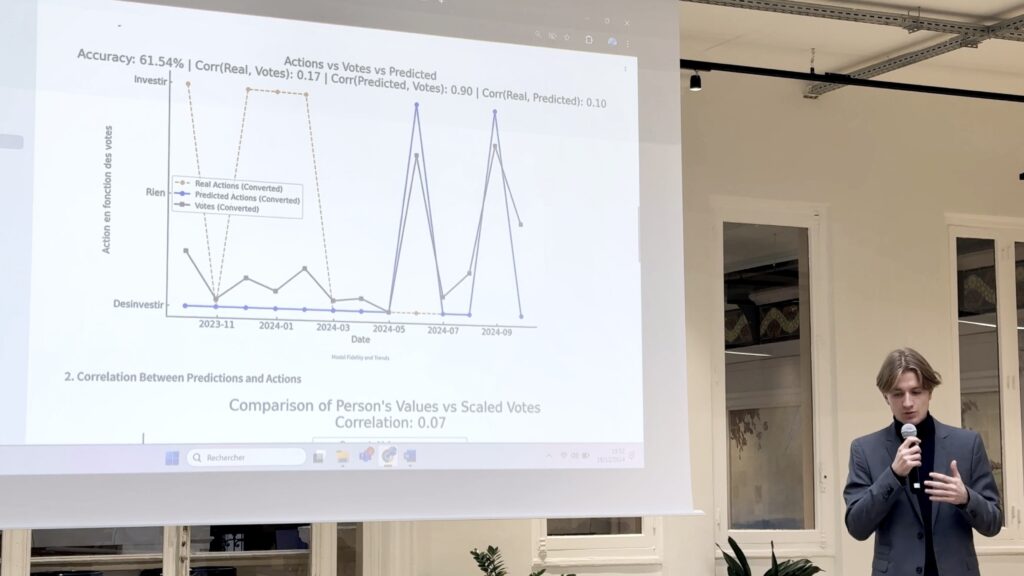
De manière plus précise, il s’agit d’un modèle expérimental de raisonnement algorithmique explicable, capable de reproduire avec une précision mesurée à 68,6 % les décisions réelles de professionnels : “Acheter”, “Conserver”, ou “Vendre”.
Cette approche dépasse le simple apprentissage automatique. Elle constitue une tentative de modéliser la rationalité humaine et ses biais à partir de données ouvertes, afin d’outiller les décideurs avec une intelligence stratégique qui complète, plutôt que remplacer, leur propre jugement.
L’intelligence stratégique alternative se distingue des systèmes classiques de veille ou de data science par trois caractéristiques :
- L’intégration du contexte humain : elle tient compte de la psychologie, du langage, et des comportements observables des acteurs.
- L’utilisation de données ouvertes et non structurées : presse, publications, signaux sociaux, événements institutionnels.
- La simulation du raisonnement collectif : elle cherche à reproduire la logique d’un groupe humain, avec ses arbitrages, ses désaccords, et sa recherche de consensus.
Dans ce modèle, la décision ne résulte pas uniquement d’une corrélation statistique ; elle émerge d’une cohérence cognitive entre signaux économiques, émotions publiques, et personnalité décisionnelle.
L’algorithme ne cherche pas à “avoir raison” sur le marché, mais à comprendre comment et pourquoi un humain rationnel dans un contexte donné déciderait d’agir ainsi.
Le système intègre cinq classes de données, combinant données de marché, événements médiatiques, indicateurs comportementaux, signaux macroéconomiques et données issues de sources ouvertes comme GDELT ou LinkedIn.
Chaque source est horodatée, normalisée, et projetée dans un espace vectoriel multidimensionnel où cohabitent la rationalité économique et les signaux émotionnels.
L’architecture du modèle se déploie en quatre couches principales, formant une chaîne cohérente : perception, inférence, délibération, décision.
Un modèle BERT spécialisé extrait des traits psychologiques (établis sur la théorie du Big Five entre autres ) et des indicateurs de tonalité émotionnelle (positivité, anxiété, intensité lexicale).
Chaque manager est alors représenté par un vecteur comportemental pᵢ ∈ ℝ⁴, mesurant son profil cognitif (Introversion, Intuition, Pensée, Jugement).
À partir de ces vecteurs, le système estime la probabilité d’un biais comportemental face à un choc de marché.
L’utilité attendue d’une décision a à un instant t dépend donc non seulement des signaux économiques s(t), mais aussi de la personnalité p du décideur et du contexte informationnel c(t) :
U(a,t,p,c)=E[V(a,s(t),p,c(t))]
Ce calcul formel traduit en pratique la propension d’un individu à agir selon sa structure psychologique et son environnement cognitif.
L’originalité majeure du modèle repose sur la simulation d’un comité virtuel : plusieurs agents “virtuels” débattent, chacun porteur d’un profil de personnalité différent.
La logique suit un arbre de recherche Monte Carlo (MCTS), où chaque nœud représente une alternative stratégique (acheter, conserver, vendre) et où la décision finale résulte d’une propagation pondérée des utilités.
Cette méthode nous l’avons mis en pratique et nous l’avons adapté en moins de 3 semaines lors d’un cas pratiques, et les résultats sont remarquables :
| Indicateur |
Valeur observée |
Interprétation |
| Précision globale |
68,6 % |
Le modèle reproduit plus de deux tiers des décisions réelles. |
| Rappel sur signaux de vente |
82 % |
Capacité à détecter les réductions d’exposition en période de risque. |
| Cohérence décisionnelle |
0,89 |
Concordance logique entre contexte et action. |
| Divergence moyenne humain/modèle |
0,17 |
Écart moyen limité : comportement humain bien simulé.
|
Les performances, obtenues sans données propriétaires, démontrent la maturité de l’OSINT comme source d’intelligence stratégique : les données publiques, lorsqu’elles sont correctement traitées et interprétées, peuvent rivaliser avec des sources fermées.
Conclusion
Ainsi, ces cas pratiques montrent que l’OSINT est aujourd’hui une source de données essentielle pour élaborer des stratégies, anticiper des risques et les comprendre. De ce fait, l’OSINT est utilisé dans de nombreux domaines et, selon nous, ne peut plus être ignoré dans un projet lié à la data. Dans notre cas, son usage concret en fait même l’un des piliers de la création de notre entreprise.
À travers ce cas consacré à l’open source intelligence, Baptiste et Alexandre démontrent comment la pédagogie des formations conjointes Mines Paris – PSL et Albert School permet aux étudiants de s’approprier des enjeux complexes et actuels par la pratique. En concevant un outil d’apprentissage ancré dans des situations réelles, ils illustrent une approche de l’enseignement qui forme des profils capables d’analyser l’information, d’en évaluer la fiabilité et de la transformer en levier stratégique. Une démarche qui reflète l’ambition de Mines Paris – PSL : préparer des décideurs éclairés, aptes à évoluer dans des environnements incertains et fortement informationnels.